
Code Reviews are required for auditing an application’s source code by people other then the author
Goal: identify errors and mistakes in the code
Benefits of a code review:
- Get another perspective
- Transfer knowledge
- Find errors and weaknesses early like CWE Top 25
- Reduce rework and testing effort
Testing ≠ Code Review
Testing isn’t enough to find Security issues. The table below shows what both have in common and where they differ:
| Testing | Code Review |
|---|---|
| Finding errors | Finding errors |
| Mainly for functional correctness | Functional correctness AND code quality |
| Can be (fully) automated | Cannot be fully automated |
| Code must be compiled | Can be done early, compilable code not always required |
Code Review Styles
A code review usually consists out of two parts a manual and an automated one. First at all, get a feeling about the code by using some automated tools like a SAST Scanner. Inspect the architecture diagrams (or get some created if they are missing), use some grep statements or SemGrep, and check for code parts with missing code coverage. Also you can create a Threat Model to derive a prioritized list for the review in a more risk based approach.
Manual Code Review
The manual part of a code review, is the part which requires the most effort. Therefore you’ll come fast to a prioritization problem. Since you can’t inspect everything, you have to inspect what probably has vulnerabilities. To find vulnerable parts in the code, you can relay on three typical approaches:
- Code coverage - check what has NOT been tested. If there is NO test at all, plan in some more time and try an automated approach like fuzzing to find weak spots
- Prediction - what history says is vulnerable will also reveal something that you currently might watch right now
- Static analysis - learn what tools say is vulnerable or based on linting, has been written sloppy/hastily by the author. Where functional bugs sum up - also security will suffer.
Before we start with the process it’s a good idea to get an overview about who’s participating in a code review and define the roles:
Author: Can answer any specific questions and help to reveal blind spots
Moderator/Inspection Leader: Responsible for planning and organizational tasks. Takes over the moderation of the meeting and also organizes follow-ups if issues or concerns were found
Recorder: Documents faults, actions, decisions made in the meeting
Reader (not the author): Leads through the review
People with readability, but objectivity: People who are experienced with security, close colleagues, system architects, developer working on the same project but in a different team, consultants and experienced developers from other parts of the company.
Manual Code Review - as a process
Code Review Processes vary widely in their formality, focus. The most two common types are the inspection and the walkthrough.
Inspection – most formal process
- Separated roles
- Usage of Checklists
- Formal collection of metrics defects
Walkthrough – less formal process
- Author = Moderator, Reader
- Driven by author’s goal
To have a better understanding, let’s go through the inspection:

Planning:
- Author initiates planning once code ready
- Author and Moderator specify scope of the review
- Moderator identifies other participants
Preparation:
- Reviewers examine code with respect to the scope
- Reviewers use checklists and analysis tools
- Reviewers mark bugs found
Meeting:
- Reader presents the code
- Reviewers comment and ask questions
- Recorder notes comments, suggestions, decisions
- Meeting conclusion
- Code is accepted (minor rework)
- Code is accepted after reworked is verified
- Code cannot be accepted without re-inspection
Rework:
- Author addresses issues recording the meeting
Follow-up:
- Moderator verifies all changes made correctly
- Author checks in corrected code
Inspection Checklist
To have a better guidance it’s a good idea to create a checklist. To create one it’s a good idea to think about the following things:
- What will you talk about?
- Identify relevant aspects
- Assets from risk analysis (Protection Poker)
- Threats from your threat models
- Malicious actors from your requirements
- Abuse and misuse cases from your requirements
- Walk through the functionality of the code
- Look for missing code more than wrong code
- “If they missed this, then they probably missed that” Look for too much complexity, functionality
- Look for common defensive coding mistakes
- Common Vulnerabilities (e.g., SQL Injection, XSS, Path Traversal, Input Validation, and much more
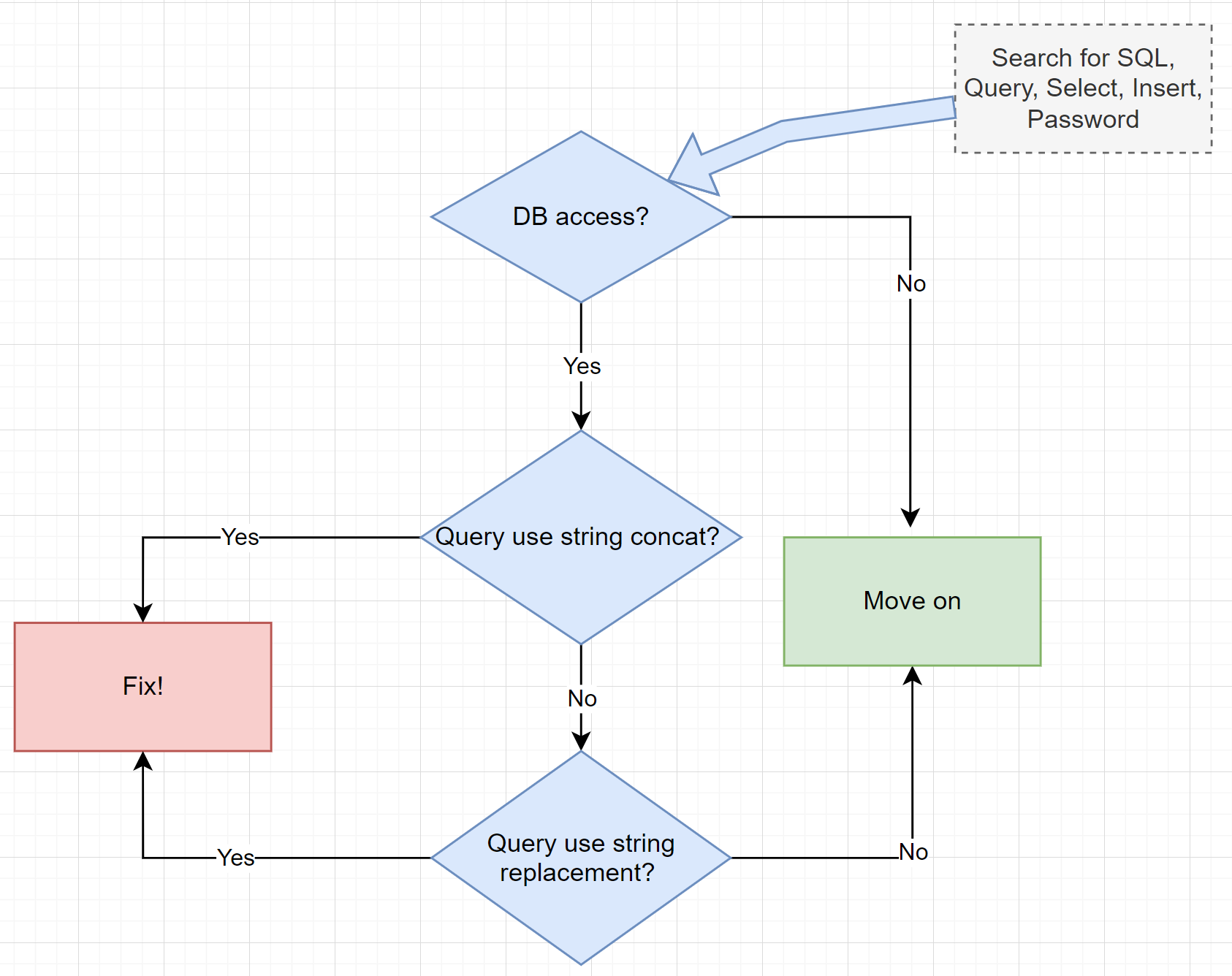
Source: Michael Howard, “A Process for Performing Security Code Reviews.” IEEE Security & Privacy, July 2006.
Key points of a manual code review
- Assign different roles for a review (Moderator, Reader, Recorder…)
- Decide for a process and adhere to it
- Double-Check your Checklist and let it review by other
- Concentrate on faults that are hardly identifiable via testing, e.g., design flaws
- Check configurations like IAM or S3 Bucket-Policies, WebServer Configuration, places where SSL is setup, spots where a crypto library is used, …
Automated Code Review
Like spoiled a multiple time above, let’s discuss the part which can be automated in a code review. The main magic here can be done with static analysis - so let’s get started:
Static analysis:
- Analyzing code without executing it
- Manual static analysis == code reviews
- Think: sophisticated compiler warnings
Automated Static Analysis tools:
- Scan the whole codebase
- Provide warnings of common coding mistakes (dead code, hardcoded credentials, null pointer, API misuse…)
- Use a variety of methods
- Fancy grep searches or dig deeper into SemGrep
- Model checking
- Data flow analysis
Key points:
- Code reviews require expertise in secure programming (I’ll write about this soon)
- Humans are fallible and miss faults
- Manual code reviews are slow but have a high chance to find something.
- Can be part of a nightly build or integrated in a CI/CD pipeline
How Static Analysis works
To see how automation can help you it’s a good idea to take a look under the hood. Time for an excursion and check out how static analysis works works internal.
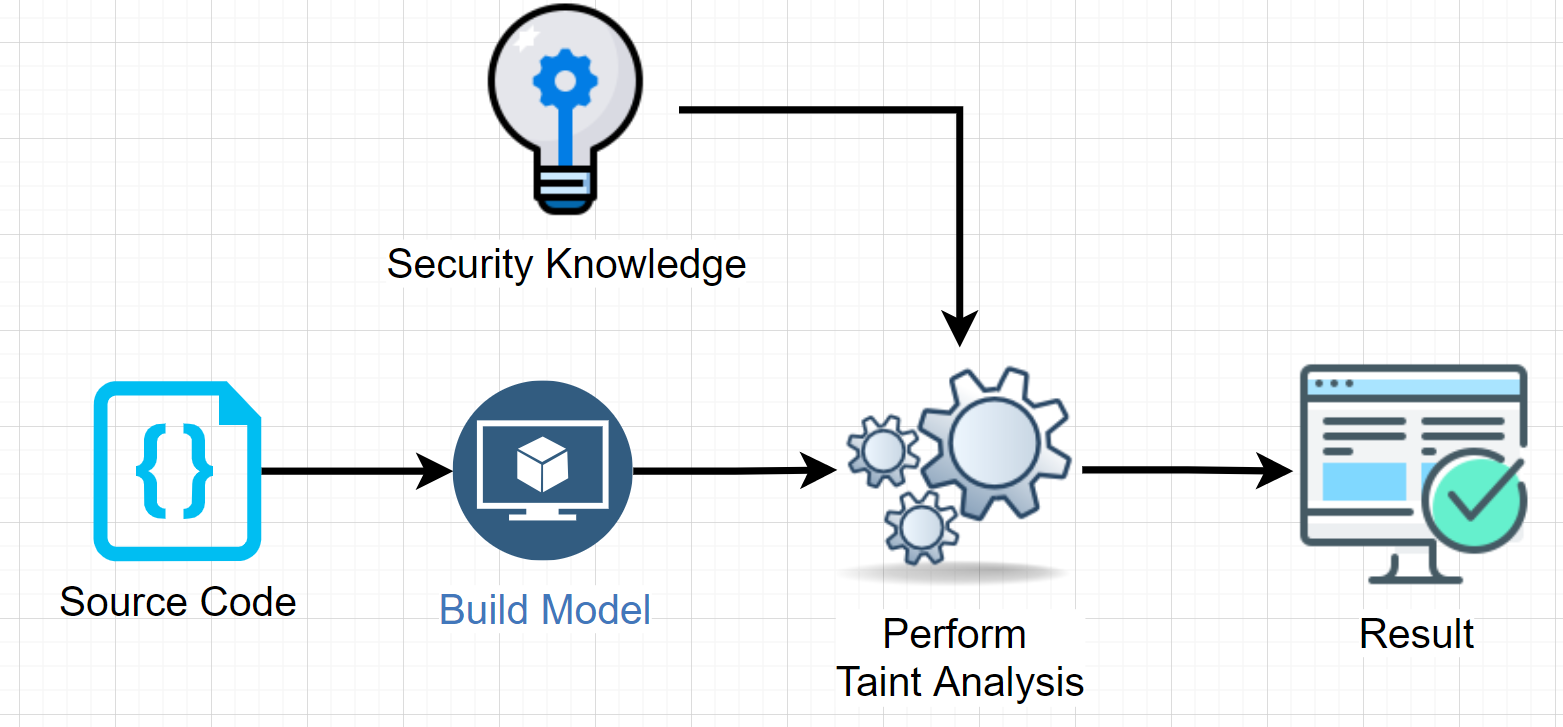
Source: Brian Chess and Jacob West, Secure Programming with Static Analysis, Addison-Wesley, 2007
Let’s discuss the entities shown in the picture above.
Build Model
Parse method (as source or bytecode) and convert it into a control-flow graph (CFG). The CFG consists of nodes which represents simplified statements. The edges are possible control flow between such statements.

Perform Taint Analysis
During the taint analysis the flow of the data is tracked from the source to the sink.
Source (( <-)): Spot where data comes into the program Sink (( ->)): A function that consumes the data
The taint analysis reports a vulnerability if:
- Data comes from an untrusted source
- Data get’s consumed by a dangerous sink
- No sanitize function is implemented between source and sink
Example for a taint analysis of SQL injection issues

The code above shows some Java code that processes an HTTP request, get’s the Student ID back and queries the database for additional information about the student. Inside the code is the source and sink displayed. Since the code is looking a little messy it’s a good idea to check the states between them and display it as a CFG and inspect the tainted values:

The SQL example aboves show’s the analysis of ONE function. Time to check the difference of the procedural analysis:
- INTRAprocedural Analysis: Analysis of an individual function
- INTERprocedural Analysis: Follow control and data flow across
Security knowledge
In the steps before we identified possible issues, now it’s time to spice everything up with some Security. Therefore we need an interpretation of results and check which kind of Security knowledge is required for configuring a static analysis tool:
- What are the data sources?
- What are the data sinks?
- What sources are untrusted?
- Which sinks are dangerous?
- WHich functions sanitize data?
Result
Time to check the results beside of true positve/negatives findings it’s always a good idea to check for design flaws in the manual review since they are very hard to identify. The main goal of your Security knowledge is required to rate the results. But we also need to talk about two things we didn’t discuss yet:

False positives:
- Static analysis reports faults that don’t exist
- Complex control or data flow may confuse analysis
False negatives:
- Static analysis fails to discover faults
- Code complexity or missing rule
Additional sources and info:
- OWASP Code Review Guide v2 (2017)
- Best Kept Secrets of Peer Code Review (Jason Cohen et al., 2006)
- Security Code Review 101 (Paul Ionescu, 2019)
- Code Review vs. Testing (Codacy, 2016)
- Rick Kuipers on The Science of Code Reviews (DPC 2018)
- Security Code Review 101 with Paul Ionescu! (OWASP DevSlop Show, 2019)
- Let’s play a game: what is the deadly bug here? (LiveOverflow, 2018)
- Sources and Sinks – Code Review Basics (LiveOverflow, 2018)